Odabrani naučni radovi

Monolingual, multilingual and cross-lingual code comment classification
Code comments are one of the most useful forms of documentation and metadata for understanding software implementation. Previous research on code comment classification has focused only on comments in English, typically extracted from a few programming languages. This paper addresses the problem of code comment classification not only in the monolingual setting, but also in the multilingual and cross-lingual one, in order to examine whether they can outperform the traditional monolingual approach. To tackle this task, we introduce a novel, publicly available code comment dataset, consisting of over 10,000 code comments collected from software projects written in eight programming languages (C, C++, C#, Java, JavaScript/TypeScript, PHP, Python, and SQL). About half of them are written in Serbian while the other half are written in English. This dataset was manually annotated according to a newly proposed taxonomy of code comment categories. We fine-tune and evaluate multiple monolingual and multilingual pre-trained neural language models on the code comment classification task and compare their performances to several baselines. The best results for Serbian comments are obtained using the monolingual neural model BERTić, trained on Serbian and closely related languages. On the other hand, the optimal choice for English is the multilingual neural model multilingual BERT, which successfully extracts useful patterns from data in both languages. Although the cross-lingual setting shows some promise for simple binary classification, it has yet to reach sufficiently high performance levels for practical use. We also analyze model performance across different programming languages.
In EAAI, 2023.
Više informacija
PDF
Programski kod
Skup podataka
ReLDI tokenizator za srpski
Stemeri za srpski i hrvatski
Lematizator za srpski
FastText vektori značenja reči za srpski (srpski veb korpus srWaC)
FastText vektori značenja reči za srpski (Common Crawl)
FastText vektori značenja reči za engleski
BERTić LLM za srpski
ELECTRA LLM za engleski
Multilingual BERT LLM
XLM-RoBERTa LLM

Metodologija rešavanja semantičkih problema u obradi kratkih tekstova napisanih na prirodnim jezicima sa ograničenim resursima
Statistički pristupi obradi prirodnih jezika tipično zahtevaju značajne količine anotiranih podataka, a često i različite pomoćne jezičke alate, što ograničava njihovu primenu u resursno ograničenim situacijama. U ovoj disertaciji predstavljena je metodologija razvoja statističkih rešenja u semantičkoj obradi prirodnih jezika sa ograničenim resursima. Ovakvi jezici se odlikuju ne samo limitiranim brojem postojećih jezičkih resursa, već i ograničenim mogućnostima za razvoj novih skupova podataka i namenskih alata i algoritama.
Predložena metodologija je usredsređena na kratke tekstove zbog njihove rasprostranjenosti u digitalnoj komunikaciji i zbog veće složenosti njihove semantičke obrade. Metodologija obuhvata sve faze izrade statističkih rešenja, od prikupljanja tekstualnog sadržaja, preko anotacije podataka, do formulisanja, obučavanja i evaluacije modela mašinskog učenja. Njena upotreba je detaljno ilustrovana na dva semantička problema – analizi sentimenta i određivanju semantičke sličnosti. Kao primer jezika sa ograničenim resursima korišćen je srpski jezik, ali se predložena metodologija može primeniti i na druge jezike iz ove kategorije.
Pored opšte metodologije, u doprinose ove disertacije spada razvoj novog, fleksibilnog sistema označavanja sentimenta kratkih tekstova, nove metrike za utvrđivanje ekonomičnosti anotacije, kao i nekoliko novih modela za određivanje semantičke sličnosti kratkih tekstova. Rezultati disertacije uključuju i kreiranje prvih javno dostupnih anotiranih skupova podataka za probleme analize sentimenta i određivanja semantičke sličnosti kratkih tekstova na srpskom jeziku, razvoj i evaluaciju većeg broja modela na ovim problemima, i prvu komparativnu evaluaciju većeg broja alata za morfološku normalizaciju na kratkim tekstovima na srpskom jeziku.
Predložena metodologija je usredsređena na kratke tekstove zbog njihove rasprostranjenosti u digitalnoj komunikaciji i zbog veće složenosti njihove semantičke obrade. Metodologija obuhvata sve faze izrade statističkih rešenja, od prikupljanja tekstualnog sadržaja, preko anotacije podataka, do formulisanja, obučavanja i evaluacije modela mašinskog učenja. Njena upotreba je detaljno ilustrovana na dva semantička problema – analizi sentimenta i određivanju semantičke sličnosti. Kao primer jezika sa ograničenim resursima korišćen je srpski jezik, ali se predložena metodologija može primeniti i na druge jezike iz ove kategorije.
Pored opšte metodologije, u doprinose ove disertacije spada razvoj novog, fleksibilnog sistema označavanja sentimenta kratkih tekstova, nove metrike za utvrđivanje ekonomičnosti anotacije, kao i nekoliko novih modela za određivanje semantičke sličnosti kratkih tekstova. Rezultati disertacije uključuju i kreiranje prvih javno dostupnih anotiranih skupova podataka za probleme analize sentimenta i određivanja semantičke sličnosti kratkih tekstova na srpskom jeziku, razvoj i evaluaciju većeg broja modela na ovim problemima, i prvu komparativnu evaluaciju većeg broja alata za morfološku normalizaciju na kratkim tekstovima na srpskom jeziku.
Doktorska disertacija, Univerzitet u Beogradu - Elektrotehnički fakultet, 2020.

A versatile framework for resource-limited sentiment articulation, annotation, and analysis of short texts
Choosing a comprehensive and cost-effective way of articulating and annotating the sentiment of a text is not a trivial task, particularly when dealing with short texts, in which sentiment can be expressed through a wide variety of linguistic and rhetorical phenomena. This problem is especially conspicuous in resource-limited settings and languages, where design options are restricted either in terms of manpower and financial means required to produce appropriate sentiment analysis resources, or in terms of available language tools, or both. In this paper, we present a versatile approach to addressing this issue, based on multiple interpretations of sentiment labels that encode information regarding the polarity, subjectivity, and ambiguity of a text, as well as the presence of sarcasm or a mixture of sentiments. We demonstrate its use on Serbian, a resource-limited language, via the creation of a main sentiment analysis dataset focused on movie comments, and two smaller datasets belonging to the movie and book domains. In addition to measuring the quality of the annotation process, we propose a novel metric to validate its cost-effectiveness. Finally, the practicality of our approach is further validated by training, evaluating, and determining the optimal configurations of several different kinds of machine-learning models on a range of sentiment classification tasks using the produced dataset.
In PLoS ONE, 2020.
SETimes.SR – A Reference Training Corpus of Serbian
In this paper we present SETimes.SR – a gold standard dataset for Serbian, annotated with regard to document, sentence, and token segmentation, morphosyntax, lemmas, dependency syntax, and named entities. We describe the annotation layers and provide a basic statistical overview of them, and we discuss the method of encoding them in the CoNLL and the TEI format. In addition, we compare the SETimes.SR corpus with the older SETimes.HR dataset in Croatian.
JT-DH, 2018.

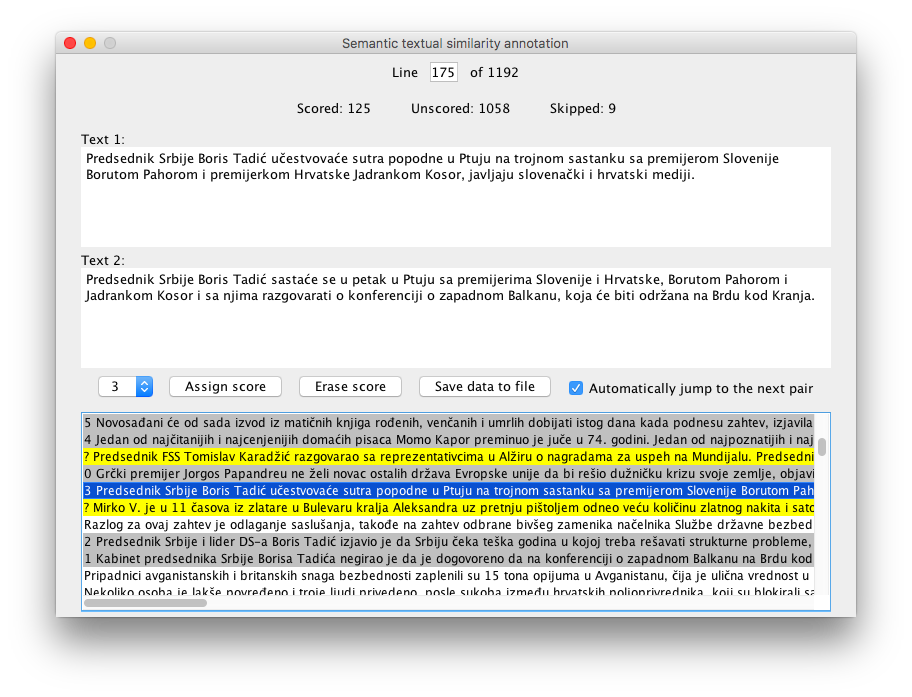
Fine-grained Semantic Textual Similarity for Serbian
Although the task of semantic textual similarity (STS) has gained in prominence in the last few years, annotated STS datasets for model training and evaluation, particularly those with fine-grained similarity scores, remain scarce for languages other than English, and practically non-existent for minor ones. In this paper, we present the Serbian Semantic Textual Similarity News Corpus (STS.news.sr) – an STS dataset for Serbian that contains 1192 sentence pairs annotated with fine-grained semantic similarity scores. We describe the process of its creation and annotation, and we analyze and compare our corpus with the existing news-based STS datasets in English and other major languages. Several existing STS models are evaluated on the Serbian STS News Corpus, and a new supervised bag-of-words model that combines part-of-speech weighting with term frequency weighting is proposed and shown to outperform similar methods. Since Serbian is a morphologically rich language, the effect of various morphological normalization tools on STS model performances is considered as well. The Serbian STS News Corpus, the annotation tool and guidelines used in its creation, and the STS model framework used in the evaluation are all made publicly available.
LREC, 2018.
Više informacija
PDF
Programski kod
Skup podataka
Alat za anotaciju STSAnno
Uputstva za anotaciju semantičke sličnosti kratkih tekstova
Srpski web korpus srWaC
ReLDI tokenizator za srpski
Stemeri za srpski i hrvatski
BTagger za srpski
HunPos i CST modeli za hrvatski
ReLDI tager i lematizator za srpski i hrvatski

Reliable Baselines for Sentiment Analysis in Resource-Limited Languages: The Serbian Movie Review Dataset
Collecting data for sentiment analysis in resource-limited languages carries a significant risk of sample selection bias, since the small quantities of available data are most likely not representative of the whole population. Ignoring this bias leads to less robust machine learning classifiers and less reliable evaluation results. In this paper we present a dataset balancing algorithm that minimizes the sample selection bias by eliminating irrelevant systematic differences between the sentiment classes. We prove its superiority over the random sampling method and we use it to create the Serbian movie review dataset – SerbMR – the first balanced and topically uniform sentiment analysis dataset in Serbian. In addition, we propose an incremental way of finding the optimal combination of simple text processing options and machine learning features for sentiment classification. Several popular classifiers are used in conjunction with this evaluation approach in order to establish strong but reliable baselines for sentiment analysis in Serbian.
LREC, 2016.