Selected Publications

Monolingual, multilingual and cross-lingual code comment classification
Code comments are one of the most useful forms of documentation and metadata for understanding software implementation. Previous research on code comment classification has focused only on comments in English, typically extracted from a few programming languages. This paper addresses the problem of code comment classification not only in the monolingual setting, but also in the multilingual and cross-lingual one, in order to examine whether they can outperform the traditional monolingual approach. To tackle this task, we introduce a novel, publicly available code comment dataset, consisting of over 10,000 code comments collected from software projects written in eight programming languages (C, C++, C#, Java, JavaScript/TypeScript, PHP, Python, and SQL). About half of them are written in Serbian while the other half are written in English. This dataset was manually annotated according to a newly proposed taxonomy of code comment categories. We fine-tune and evaluate multiple monolingual and multilingual pre-trained neural language models on the code comment classification task and compare their performances to several baselines. The best results for Serbian comments are obtained using the monolingual neural model BERTić, trained on Serbian and closely related languages. On the other hand, the optimal choice for English is the multilingual neural model multilingual BERT, which successfully extracts useful patterns from data in both languages. Although the cross-lingual setting shows some promise for simple binary classification, it has yet to reach sufficiently high performance levels for practical use. We also analyze model performance across different programming languages.
In EAAI, 2023.
Details
PDF
Code
Dataset
ReLDI tokenizer for Serbian
Stemmers for Serbian and Croatian
Lemmatizer for Serbian
FastText word embeddings for Serbian (Serbian web corpus srWaC)
FastText word embeddings for Serbian (Common Crawl)
FastText word embeddings for English
BERTić LLM for Serbian
ELECTRA LLM for English
Multilingual BERT LLM
XLM-RoBERTa LLM

A methodology for solving semantic tasks in the processing of short texts written in natural languages with limited resources
Statistical approaches to natural language processing typically require considerable amounts of labeled data, and often various auxiliary language tools as well, limiting their applicability in resource-limited settings. This thesis presents a methodology for developing statistical solutions in the semantic processing of natural languages with limited resources. In these languages, not only are existing language resources limited, but so are the capabilities for developing new datasets and dedicated tools and algorithms. The proposed methodology focuses on short texts due to their prevalence in digital communication, as well as the greater complexity regarding their semantic processing.
The methodology encompasses all phases in the creation of statistical solutions, from the collection of textual content, to data annotation, to the formulation, training, and evaluation of machine learning models. Its use is illustrated in detail on two semantic tasks – sentiment analysis and semantic textual similarity. The Serbian language is utilized as an example of a language with limited resources, but the proposed methodology can also be applied to other languages in this category.
In addition to the general methodology, the contributions of this thesis consist of the development of a new, flexible short-text sentiment annotation system, a new annotation cost-effectiveness metric, as well as several new semantic textual similarity models. The thesis results also include the creation of the first publicly available annotated datasets of short texts in Serbian for the tasks of sentiment analysis and semantic textual similarity, the development and evaluation of numerous models on these tasks, and the first comparative evaluation of multiple morphological normalization tools on short texts in Serbian.
The methodology encompasses all phases in the creation of statistical solutions, from the collection of textual content, to data annotation, to the formulation, training, and evaluation of machine learning models. Its use is illustrated in detail on two semantic tasks – sentiment analysis and semantic textual similarity. The Serbian language is utilized as an example of a language with limited resources, but the proposed methodology can also be applied to other languages in this category.
In addition to the general methodology, the contributions of this thesis consist of the development of a new, flexible short-text sentiment annotation system, a new annotation cost-effectiveness metric, as well as several new semantic textual similarity models. The thesis results also include the creation of the first publicly available annotated datasets of short texts in Serbian for the tasks of sentiment analysis and semantic textual similarity, the development and evaluation of numerous models on these tasks, and the first comparative evaluation of multiple morphological normalization tools on short texts in Serbian.
PhD Thesis, University of Belgrade - School of Electrical Engineering, 2020.

A versatile framework for resource-limited sentiment articulation, annotation, and analysis of short texts
Choosing a comprehensive and cost-effective way of articulating and annotating the sentiment of a text is not a trivial task, particularly when dealing with short texts, in which sentiment can be expressed through a wide variety of linguistic and rhetorical phenomena. This problem is especially conspicuous in resource-limited settings and languages, where design options are restricted either in terms of manpower and financial means required to produce appropriate sentiment analysis resources, or in terms of available language tools, or both. In this paper, we present a versatile approach to addressing this issue, based on multiple interpretations of sentiment labels that encode information regarding the polarity, subjectivity, and ambiguity of a text, as well as the presence of sarcasm or a mixture of sentiments. We demonstrate its use on Serbian, a resource-limited language, via the creation of a main sentiment analysis dataset focused on movie comments, and two smaller datasets belonging to the movie and book domains. In addition to measuring the quality of the annotation process, we propose a novel metric to validate its cost-effectiveness. Finally, the practicality of our approach is further validated by training, evaluating, and determining the optimal configurations of several different kinds of machine-learning models on a range of sentiment classification tasks using the produced dataset.
In PLoS ONE, 2020.
SETimes.SR – A Reference Training Corpus of Serbian
In this paper we present SETimes.SR – a gold standard dataset for Serbian, annotated with regard to document, sentence, and token segmentation, morphosyntax, lemmas, dependency syntax, and named entities. We describe the annotation layers and provide a basic statistical overview of them, and we discuss the method of encoding them in the CoNLL and the TEI format. In addition, we compare the SETimes.SR corpus with the older SETimes.HR dataset in Croatian.
In JT-DH, 2018.

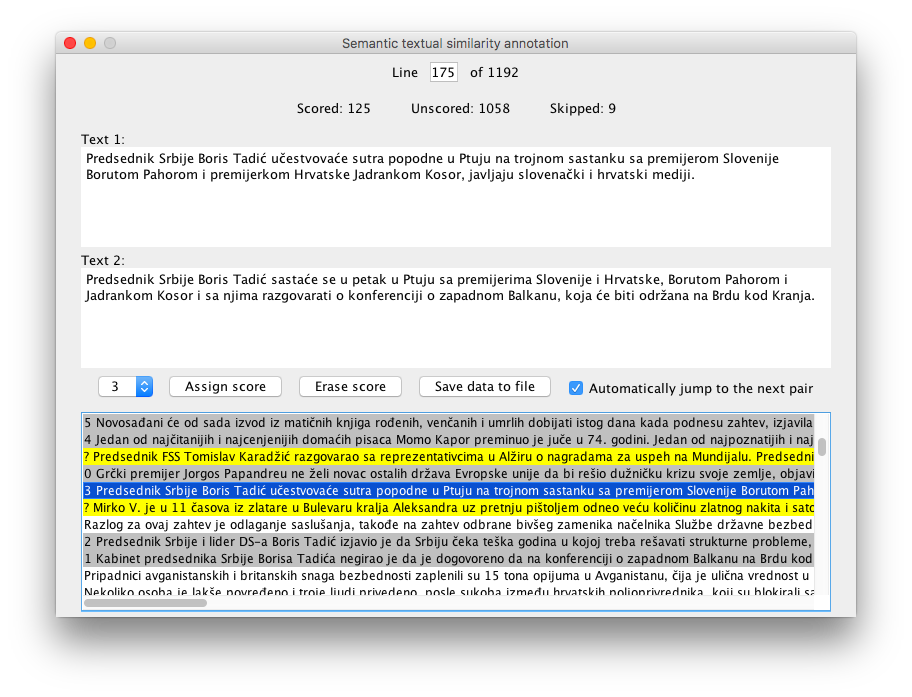
Fine-grained Semantic Textual Similarity for Serbian
Although the task of semantic textual similarity (STS) has gained in prominence in the last few years, annotated STS datasets for model training and evaluation, particularly those with fine-grained similarity scores, remain scarce for languages other than English, and practically non-existent for minor ones. In this paper, we present the Serbian Semantic Textual Similarity News Corpus (STS.news.sr) – an STS dataset for Serbian that contains 1192 sentence pairs annotated with fine-grained semantic similarity scores. We describe the process of its creation and annotation, and we analyze and compare our corpus with the existing news-based STS datasets in English and other major languages. Several existing STS models are evaluated on the Serbian STS News Corpus, and a new supervised bag-of-words model that combines part-of-speech weighting with term frequency weighting is proposed and shown to outperform similar methods. Since Serbian is a morphologically rich language, the effect of various morphological normalization tools on STS model performances is considered as well. The Serbian STS News Corpus, the annotation tool and guidelines used in its creation, and the STS model framework used in the evaluation are all made publicly available.
In LREC, 2018.

Reliable Baselines for Sentiment Analysis in Resource-Limited Languages: The Serbian Movie Review Dataset
Collecting data for sentiment analysis in resource-limited languages carries a significant risk of sample selection bias, since the small quantities of available data are most likely not representative of the whole population. Ignoring this bias leads to less robust machine learning classifiers and less reliable evaluation results. In this paper we present a dataset balancing algorithm that minimizes the sample selection bias by eliminating irrelevant systematic differences between the sentiment classes. We prove its superiority over the random sampling method and we use it to create the Serbian movie review dataset – SerbMR – the first balanced and topically uniform sentiment analysis dataset in Serbian. In addition, we propose an incremental way of finding the optimal combination of simple text processing options and machine learning features for sentiment classification. Several popular classifiers are used in conjunction with this evaluation approach in order to establish strong but reliable baselines for sentiment analysis in Serbian.
In LREC, 2016.