STSAnno - a tool for semantic textual similarity annotation
STSAnno is a tool written in Java for offline semantic textual similarity (STS) annotation. It allows the user/annotator to assign semantic similarity scores to a corpus of text/sentence pairs.
File format
On startup, the program asks the user to select the input file. The expected input is a UTF-8-encoded TXT file that contains the STS corpus to be annotated. The expected format of the corpus file is one line per text/sentence pair. Texts in a pair should be tab-separated. The annotated corpus generated as program output has a similar tab-separated structure, with three columns - the first one contains the similarity score, while the second and the third contain the texts in a pair.
Tool interface
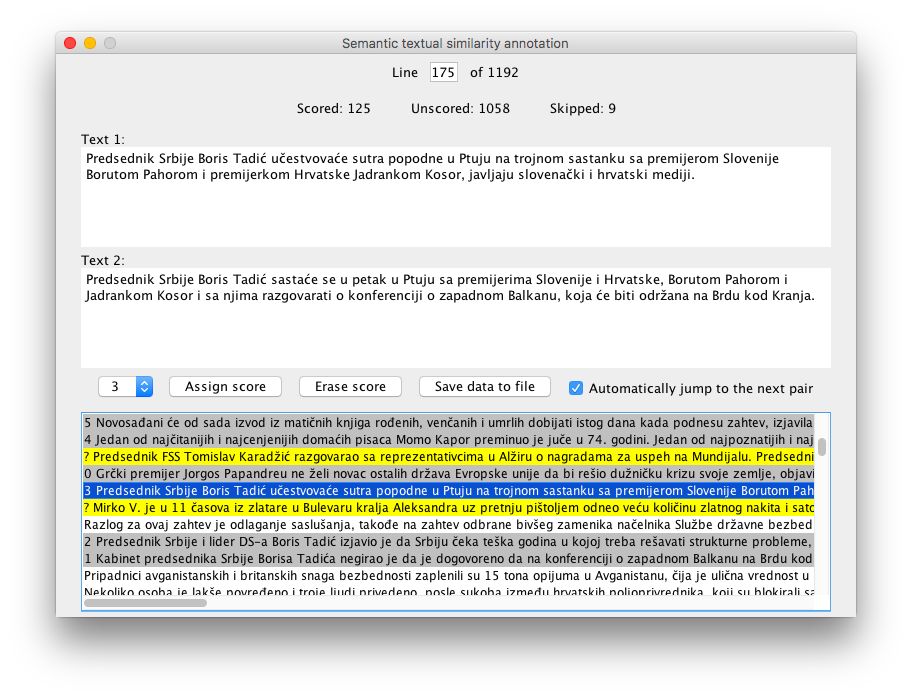
The annotator can view in parallel two short texts whose level of semantic similarity should be evaluated. A similarity score in the range 0-5 can then be assigned to the text pair. A special symbol can also be used to mark the pair in order to temporarily skip it, which can be useful when faced with difficult examples. Existing scores and symbols can be erased or rewritten. In the top of the window the program displays progress info - the number of scored, unscored, and skipped text pairs.
The user can annotate text pairs in the order in which they are contained in the corpus file or in any other order by using the scroll pane that lists all the pairs from the corpus. It is also possible to jump directly to a given line within the corpus file, via the appropriate text field in the top of the window. The program is also capable of jumping automatically to the first unscored text pair after a score is assigned to the current pair. If this option is enabled and no unscored pairs remain, the program jumps to the first skipped pair. If there are also no skipped pairs, the program selects the first pair in the corpus.
Screenshot of STSAnno during the annotation of the Serbian STS News Corpus:
Saving the annotations
The output of the program is saved to the corpus file given to the program as input i.e. the input file is overwritten with (partially) annotated data. This allows the user to work with only one file throughout the annotation process. The corpus in its current annotation state can be saved to the file using the designated button. In addition, the program automatically saves its output when the main window is closing.
Running the program
Aside from the source code in the repository, a runnable .jar file is also available for download. STSAnno can be started from the command line interface using the .jar file with the following command:
java -jar STSAnno.jar
References
If you wish to use STSAnno in your paper or project, please cite:
Fine-grained Semantic Textual Similarity for Serbian, Vuk Batanović, Miloš Cvetanović, Boško Nikolić, in Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), pp. 1370-1378, Miyazaki, Japan (2018).
Additional Documentation
All methods contain documentation and comments in English. If you have any questions about the program, please review the supplied javadoc documentation and the source code. If no answer can be found, feel free to contact me at: vuk.batanovic / at / ic.etf.bg.ac.rs
License
GNU General Public License 3.0 (GNU GPL 3.0)